To access advanced scan options, log in to Tag Inspector, select “Scanner” in the top-left corner, then select “Start A New Scan.” Type in the URL of the website you would like to scan and the number of pages you would like to scan, then select “Next Step.”
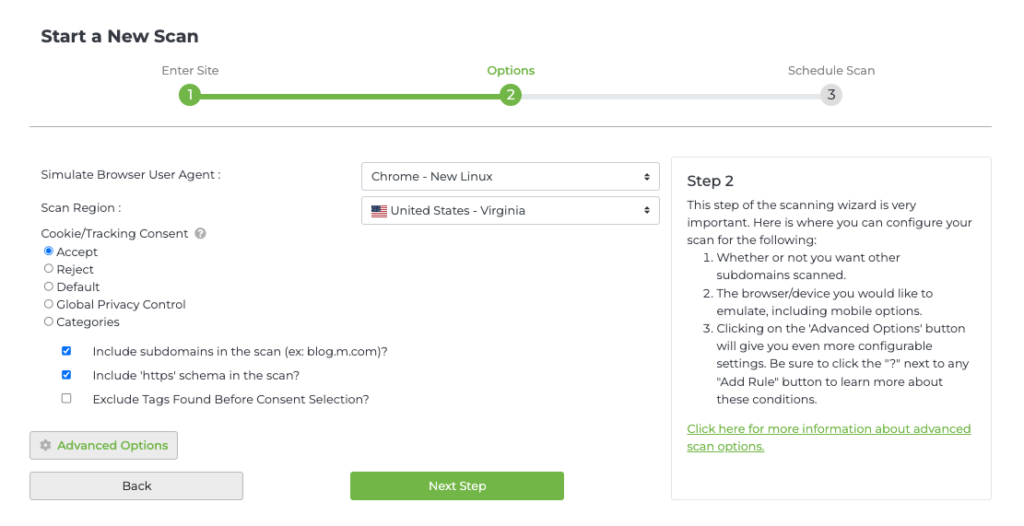
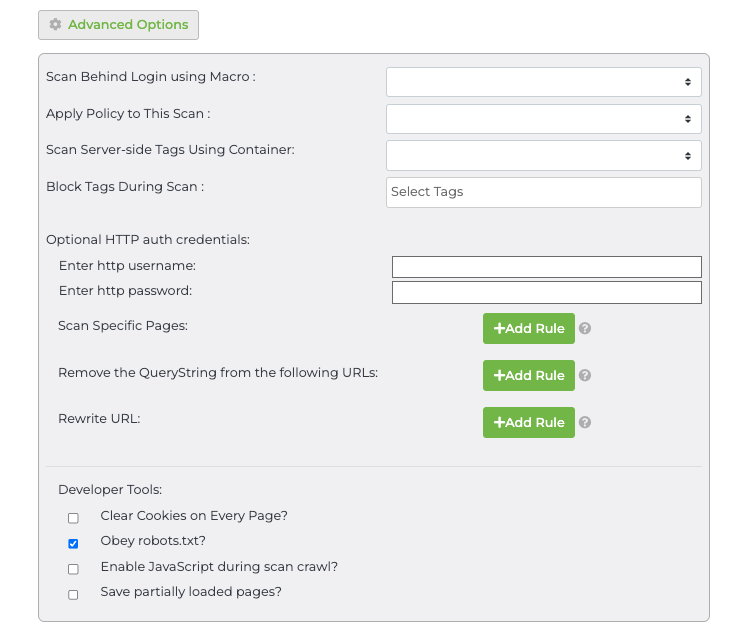
Advanced Options allows you to enable these features:
- Scan specific pages
- Remove the query string from specific URLs
- Rewrite URL
- Clear cookies on every page
Scan Specific Pages
By default, Tag Inspector will crawl any page on your site in random order. To specify only a specific page or group of pages, you can modify the crawler to only scan the URLs you want.
Example:
Say your company has multiple language versions of your site with different subdirectories to split it up, and you only want to scan the U.S. English version. If your URL structure is http://www.site.com/locale/ such as http://www.brand.com/us/en/ vs http://www.brand.com/mx/es/ you can set up a rule to scan URL contains “/us/en/”.

Select “+Add Rule” to narrow the scan results to the pages you want or do not want scanned.
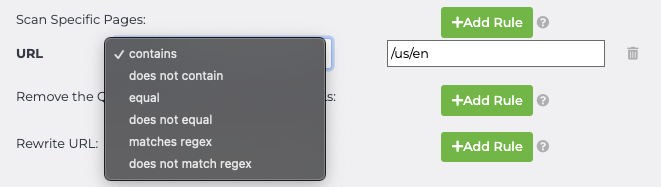
The drop-down box allows you to include/exclude or specify specific pages to scan.
Remove the query string from the following URL
Many sites utilize query string parameters to distinguish unique pages for users, though the general content (and typically tagging architecture) can be the same. To avoid scanning the same page multiple times due to unique query strings, use this feature to exclude all additional duplicate pages that contain a question mark (“?”) or hash (“#”) symbol.
Example:
Say your site has unique product pages that all have the same tagging architecture and layout, only unique content. Your site may have URLs similar to
http://www.site.com/product, http://www.site.com/product?id=1, http://www.site.com/product?id=2 etc. By removing the query string from URL contains /product/, you will set the crawler to skip the “?id=” pages and only scan http://www.site.com/product.

Select “+Add Rule” to remove the querystring from your URLS.
Rewrite URL
This feature allows you to group certain pages together that may contain the same types of tags and avoid unnecessary scanning of similar pages. This is to be used only when certain pages are confirmed to be the same, but may have different URL patterns. You can set a regex for the URL pattern you want to group, and identify the substitution URL you want all pages within that URL pattern to be grouped under.
Note: This feature is only recommended for users that know Regex syntax.
Example:
Say you have portions of your site that have unique URLs but contain the same content and tags, such as category pages. Your site URL structure may resemble this: http://www.site.com/category/food, http://www.site.com/category/snacks, http://www.site.com/category/foods-today etc. If you are confident all pages within the /category/ sub-directory are the same and can be scanned as one page, you can leverage the Rewrite URL feature by setting:
URL pattern “\/category\/(.*)” and a substitution URL “/category/”. This will group all pages with the subdirectory /category/ together.

Select “+Add Rule” to rewrite a URL pattern.
Clear cookies on every page
Tag Inspector scans every page of the website you specify over a single session, or multiple sessions in the case of large scans. Cookies set by those sessions are detected and reported in the scan report when the scan is complete. Selecting the “Clear cookies on every page” button creates a new session for each page you scan. This will give you a clear view of which pages are or are not setting cookies.
Obey robots.txt
robots.txt contain instructions for crawlers on which portions of a website they are only allowed to visit. Enabling this option will perform a more secure scan on your website but will exclude pages that the Tag Inspector Scanner is told it cannot access.