Introduction
As folks may or may not know, Tag Inspector recently celebrated its 10th year anniversary!
Indeed, from its humble beginnings, Tag Inspector has certainly come a long way. It’s been a decade of inspecting tags and providing visibility into tag architectures for site portfolios of some of the biggest brands in the known universe.
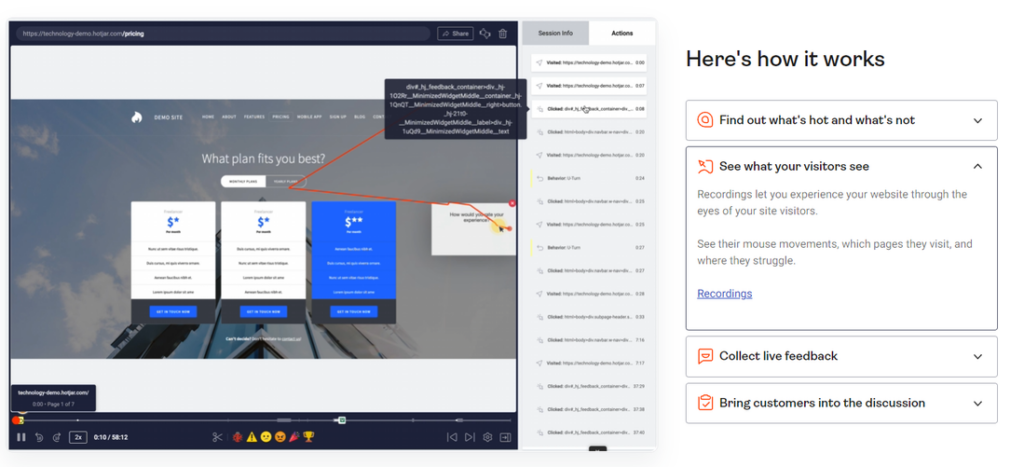
To celebrate this momentous occasion, over the next few weeks we are going to stroll through the hallowed halls of Tag Inspector history (#tag-inspector-decennial-series) and do technical deep dives into various aspects of the tool. Up for discussion today is the Tag Inspector Tag Stack Trace. One of the most useful features of the Tag Inspector tool, the Tag Inspector Tag Stack Trace shows you the load and call hierarchy of what tags are making what network requests, which are loading on your site. The one thing to always keep in mind is that whether first party or third party, direct or indirect, at the day’s end—you, the site owner—are solely responsible for all customer data that is leaving your site.
Why Use the Tag Stack Trace?
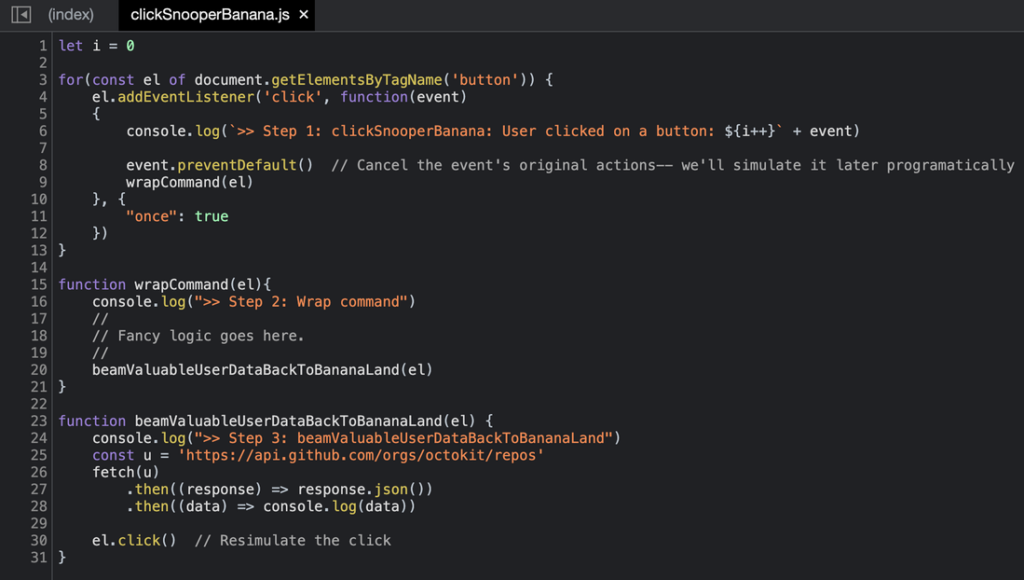
The world of piggybacking tags is rich and over the years, various tags have found all sorts of clever ways to vacuum valuable user data off of your website and then send that valuable harvested data to various third-party endpoints around the world. This has led to an advertising and audience retargeting ecosystem that is immensely valuable.
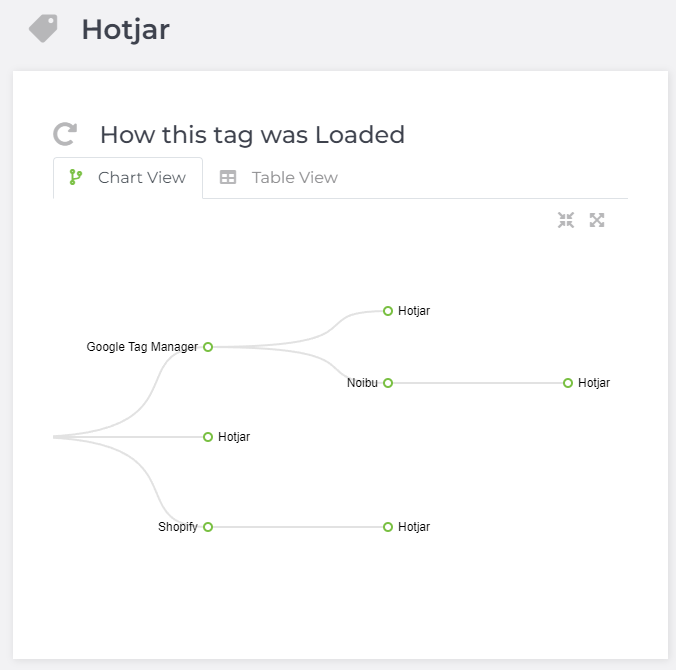
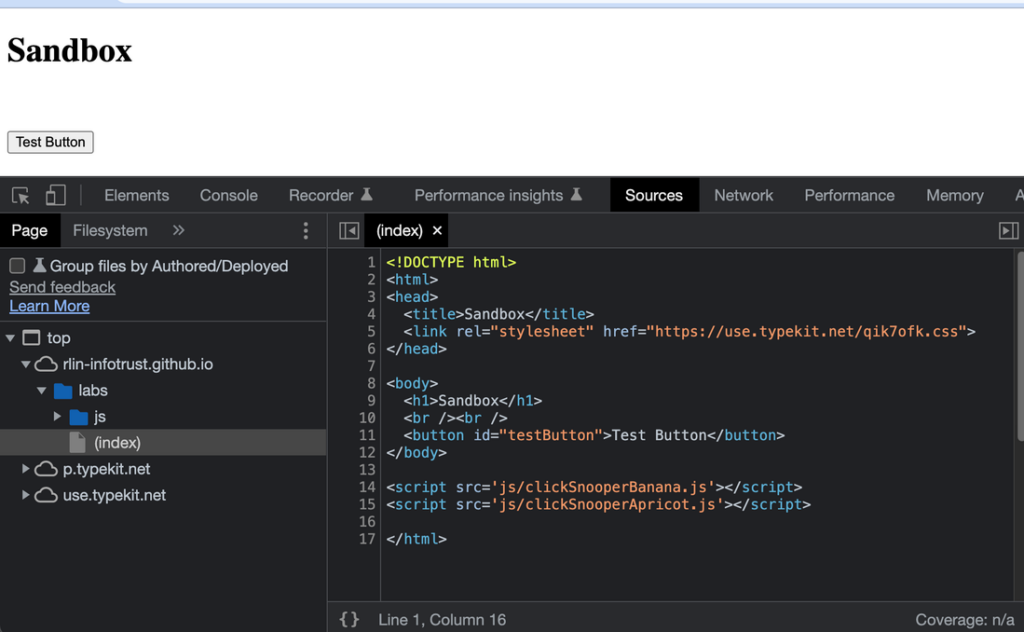
The first thing to understand about piggybacking tags is that at the highest level, there are two methods by which tags can “piggy back”. The first method is obvious and what we call an “Explicit Piggyback”—the most notable example of this is Tag Management Systems (TMS)—such as Google Tag Manager, Tealium, Adobe Launch—in which you explicitly define a piggybacked tag that you wish to load in via your TMS tag.
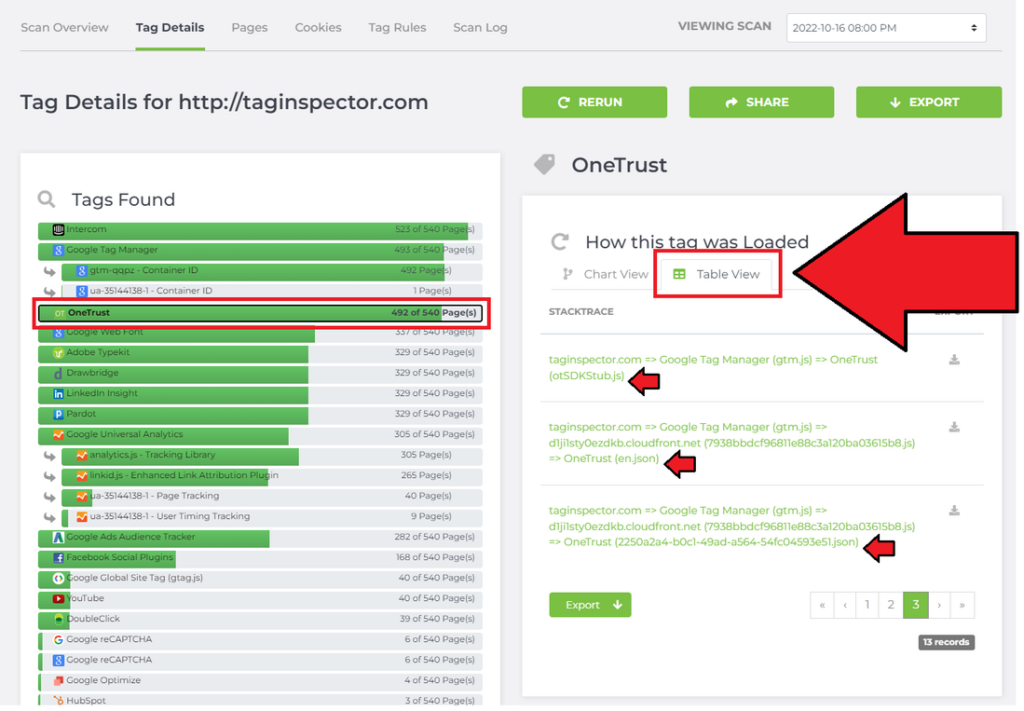
For the sake of demonstration, for method one, let’s look at the popular Consent Management Platform (CMP) tool, OneTrust. Let’s say you are interested in seeing how it loads on your site.
Method #1: Explicit Piggyback
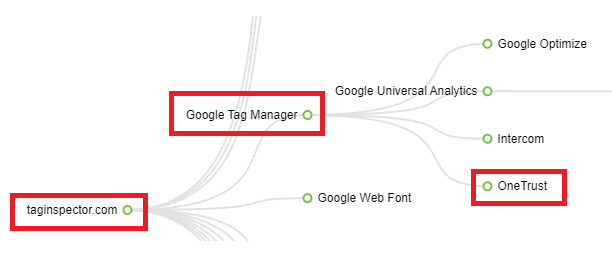
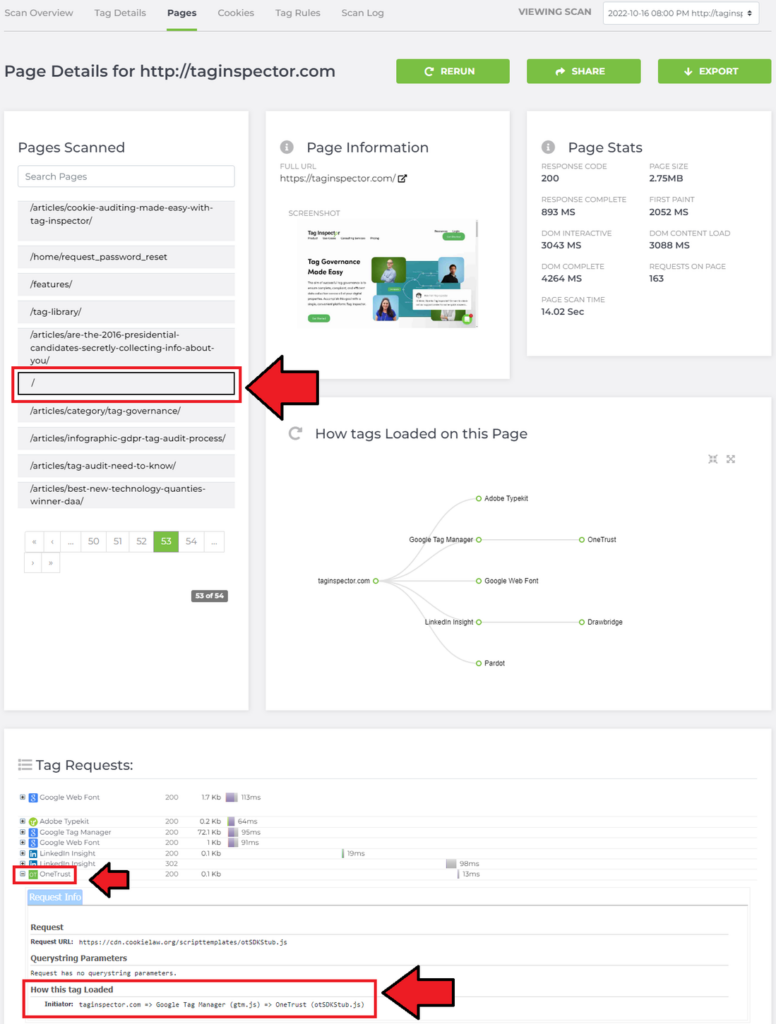
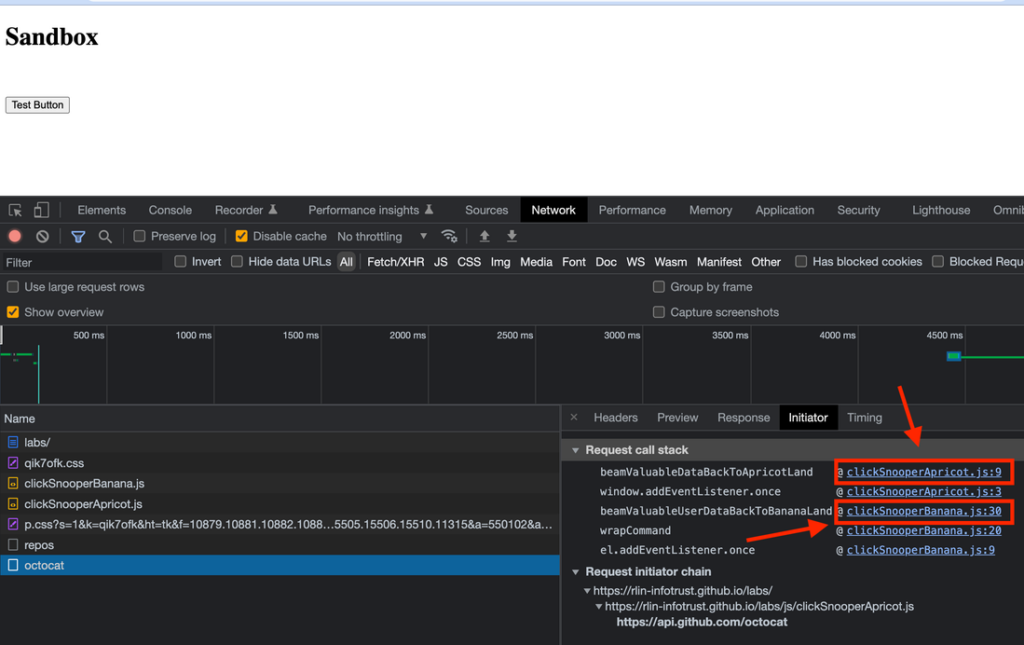
Anyone using Tag Inspector will be familiar with the tag hierarchy view which appears on the Scan Overview tab of the the Scanner module. From the the tag hierarchy view, you can easily see that OneTrust is loading from Source → Google Tag Manager → OneTrust: