 A sitemap is an easy way for the site administrators to notify a search engine’s crawlers about the organization of their site’s content. You might have seen links to sitemaps within a site that take you to a browser page having the links enlisted with hyperlinks.
A sitemap is an easy way for the site administrators to notify a search engine’s crawlers about the organization of their site’s content. You might have seen links to sitemaps within a site that take you to a browser page having the links enlisted with hyperlinks.
An XML Sitemap is slightly different. It is an XML file containing the list of URLs for a site with some additional information like:
- When the URL was last updated
- How frequently the URLs change
- It’s relative importance to other URLs
The information in this file, along with another file called robots.txt, communicates to the crawler the URLs that are available for crawling and how to intelligently crawl them.
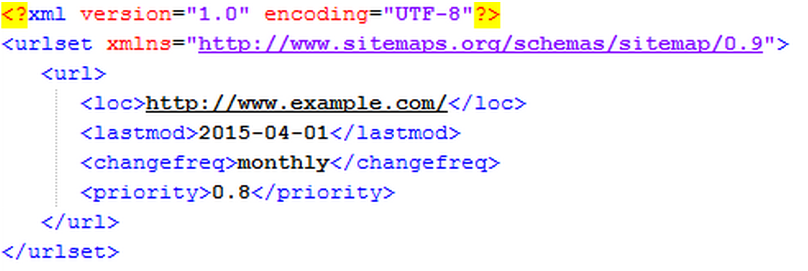
Here’s a Sample XML Sitemap having one URL:
Ideally, any crawler has the capability to read through your website’s pages and find the physical links that it has. It then crawls each of the links that it found on that page and so on (this explains why crawlers are referred to as spiders – it is a web of URLs to be crawled literally). So, if a site is well connected through links, it may be okay not to have a sitemap, but it is highly recommended to have one. Why? Because it can greatly improve the efficiency with which your site is crawled.
Let’s take a few use cases to understand the need for Sitemap:
- If you have a very large website, the search engine crawlers like Google’s may miss certain updated or new pages on your website. Having a sitemap solves this issue as the crawler then knows the structure and composition of the site.
- If your site has isolated content which is not well connected, the crawler may not be able to find some parts of your site (the poor guy wouldn’t know that they existed if there are no links to them!). Enlisting all the pages that need to be crawled in the sitemap solves this issue, as the crawler now knows that these pages exist.
- Search engine crawlers hop from one website to another and crawl the pages, so if your site has relatively few external links, they may be missed by such crawlers. Building a sitemap resolves this issue.
- A special case for crawlers like that of Tag Inspector that crawl only one domain on request: If you want to only scan a specific set of URLs and not your complete site, you can create a sitemap of those specific URLs. This will enable Tag Inspector (or another crawler) to intelligently crawl only those parts or specific pages of your site.
So, the next question is, “Okay, I have built the sitemap and it is sitting in my site. Is that all that I need to do?”
Unfortunately, no. Once the Sitemap file is created and placed on your webserver, you need to inform the crawlers of its location. For search engines, this can be done by submitting the sitemap to them via the search engine’s submission interface or by specifying the location in your site’s robots.txt file.
The search engines can then retrieve your Sitemap and make the URLs available to their crawlers. It is recommended to have your sitemap embedded in the root of your website like this: http://www.example.org/sitemap.xml. This makes it easier for the crawlers to spot it, though it does not do away with the need of registering the sitemap with the search engines. For other crawlers like Tag Inspector, the XML sitemap can be listed as the URL to scan when setting up a new site scan.
Is there a specific set of URLs that you want to discover marketing tags on? Create a sitemap and submit it now to Tag Inspector!
